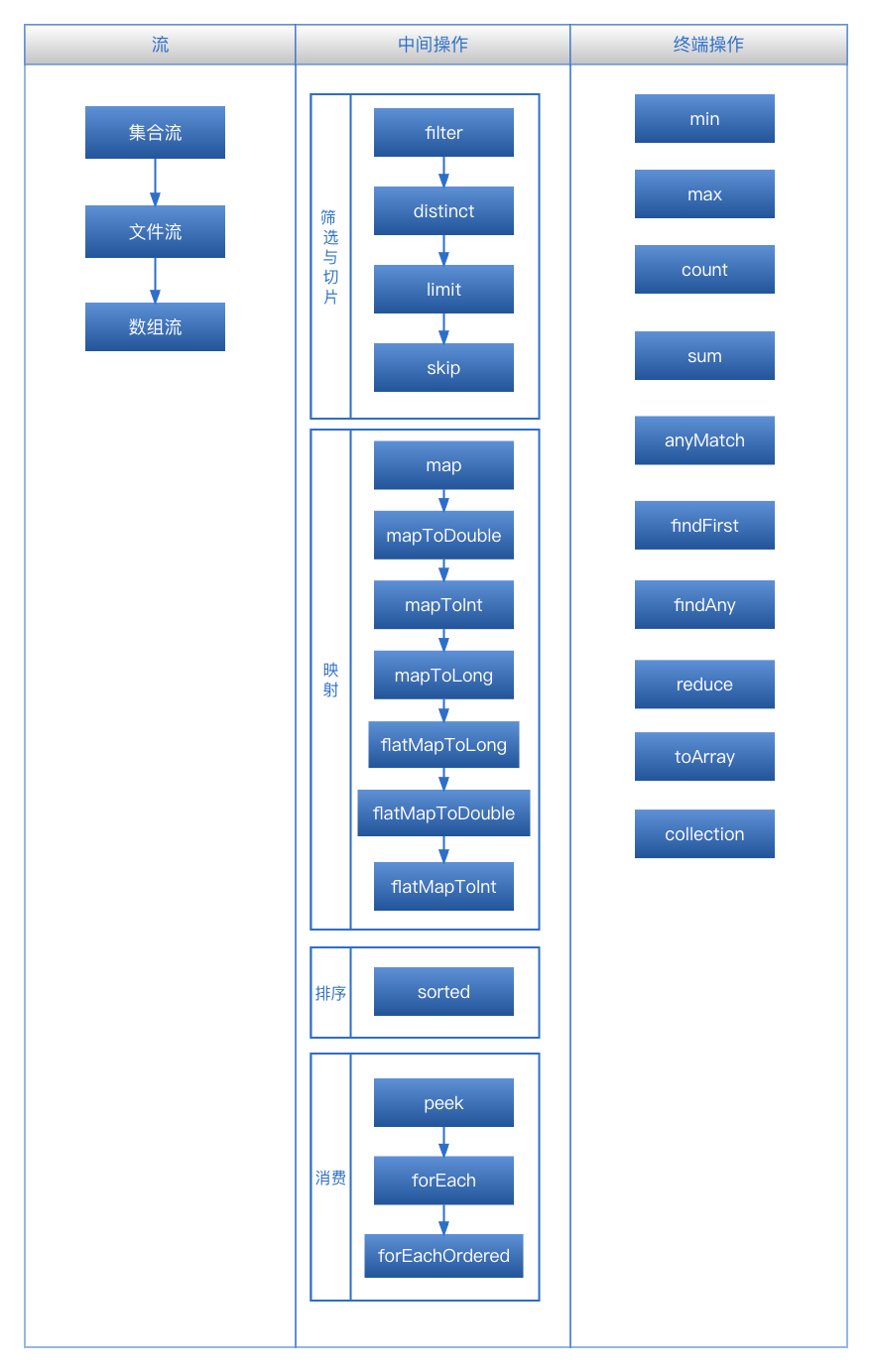
Stream API

构造一个 Stream 对象
new ArrayList<>().stream();
Arrays.stream(new String[]{});
Stream.of(new String[]{});
//构建一个空的
Stream.empty();
//连接两个 Stream对象,返回一个新的
Stream.concat(a,b);
中间操作
筛选与切片
filter
根据条件过滤
List<String> list = Arrays.asList("1","2","3","4");
list.stream().filter(i->i.equals("1")).forEach(System.out::println);
// 输出结果: 1
distinct
筛选,通过流所生成元素的 hashCode() 和 equals() 去 除重复元素。
List<String> list = Arrays.asList("1","3","3","3");
list.stream().distinct().forEach(System.out::println);
// 输出结果: 1 3
limit
截断流,使其元素不超过给定数量。
List<String> list = Arrays.asList("1","3","3","3");
list.stream().limit(2).forEach(System.out::println);
// 输出结果: 1 3
skip
跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素 不足 n 个,则返回一个空流。与 limit(n) 互补。
List<String> list = Arrays.asList("1","3","3","3");
list.stream().skip(2).forEach(System.out::println);
// 输出结果: 3 3
映射
map
接收一个函数作为参数,映射成一个新的元素
List<String> list = Arrays.asList("1","3","3","3");
List<Integer> intList = list.stream().map(i->Integer.parseInt(i)).collect(Collectors.toList());
mapToDouble
接收一个函数作为参数,产生一个新的 DoubleStream。
List<String> list = Arrays.asList("1","3","3","3");
double sum= list.stream().mapToDouble(i->Double.valueOf(i)).sum();
mapToInt
接收一个函数作为参数,产生一个新的 IntStream。
List<String> list = Arrays.asList("1","3","3","3");
int sum= list.stream().mapToInt(i->Integer.valueOf(i)).sum();
mapToLong
接收一个函数作为参数,产生一个新的 LongStream。
List<String> list = Arrays.asList("1","3","3","3");
Long sum= list.stream().mapToLong(i->Long.valueOf(i)).sum();
flatMap
接收一个函数作为参数,将流中的每个值都换成另 一个流,然后把所有流连接成一个流
List<String> fun1 = Arrays.asList("one", "two", "three");
List<String> fun2 = Arrays.asList("four", "five", "six");
Stream.of(fun1,fun2).flatMap(List::stream).forEach(System.out::println);
// 输出
// one
// two
// three
// four
// five
// six
/**
*使用map
*/
List<String> fun1 = Arrays.asList("one", "two", "three");
List<String> fun2 = Arrays.asList("four", "five", "six");
Stream.of(fun1,fun2).map(List::stream).forEach(System.out::println);
// 输出
// java.util.stream.ReferencePipeline$Head@2f00f851
// java.util.stream.ReferencePipeline$Head@4207609e
flatMapToLong
将给定的mapper函数应用于流的每个元素,并返回LongStream
List<String> list = Arrays.asList("1", "2", "3", "4", "5");
Long sum = list.stream().flatMapToLong(num -> LongStream.of(Long.parseLong(num))).sum();
flatMapToDouble
将给定的mapper函数应用于流的每个元素,并返回flatMapToDouble
List<String> list = Arrays.asList("1", "2", "3", "4", "5");
Double sum = list.stream().flatMapToDouble(num -> DoubleStream.of(Double.valueOf(num))).sum();
flatMapToInt
将给定的mapper函数应用于流的每个元素,并返回IntStream
List<String> list = Arrays.asList("1", "2", "3", "4", "5");
int sum = list.stream().flatMapToInt(num -> IntStream.of(Integer.valueOf(num))).sum();
排序
sorted
产生一个新流,其中按自然顺序排序或者按照比较器顺序排序
List<String> list = Arrays.asList("1","3","3","3");
// 自然排序
List persons = list.stream().sorted().collect(Collectors.toList());
// 自然排序 倒叙
List personsReverse = list.stream().sorted(Comparator.reverseOrder()).collect(Collectors.toList());
// 实体按照字段排序
List<User> userList = Arrays.asList(new User(18,"张三"),new User(16,"李四"),new User(20,"王五"));
userList.stream().sorted(Comparator.comparing(User::getAge)).collect(Collectors.toList());
//倒叙
userList.stream().sorted(Comparator.comparing(User::getAge).reversed()).collect(Collectors.toList());
//定制排序
List persons1 = list.stream().sorted((e1, e2) -> {
if (e1.getAge() == e2.getAge()) {
return 0;
} else if (e1.getAge() > e2.getAge()) {
return 1;
} else {
return -1;
}
}).collect(Collectors.toList());
消费
peek
用来消费 Stream 元素,peek主要被用在debug用途。不会对元素产生更改
Stream<String> a = Stream.of("a", "b", "c");
List<String> list = a.peek(e->System.out.println(e.toUpperCase())).collect(Collectors.toList());
forEach
peek 方法类似,都接收一个消费者函数式接口
List<String> list = Arrays.asList("1","3","3","3");
list.stream().forEach(System.out::println);
forEachOrdered
功能与
forEach是一样的,不同的是,forEachOrdered是有顺序保证的,也就是对 Stream 中元素按插入时的顺序进行消费
List<String> list = Arrays.asList("1","3","3","3");
list.stream().forEachOrdered(System.out::println);
终端操作
min
最小值
List<Integer> list = Arrays.asList(1,2,3,4);
list.stream().min(Integer::compareTo).get();
max
最大值
List<Integer> list = Arrays.asList(1,2,3,4);
list.stream().max(Integer::compareTo).get();
count
个数
List<Integer> list = Arrays.asList(1,2,3,4);
list.stream().count();
sum
合
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 5);
Integer sum = integers.stream()
.mapToInt(Integer::intValue)
.sum();
anyMatch
anyMatch匹配判断的条件里,任意一个元素成功,返回true
allMatch表示,判断条件里的元素,所有的都是,返回true
noneMatch跟allMatch相反,判断条件里的元素,所有的都不是,返回true
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 5);
boolean aa = integers.stream().anyMatch(i -> i.equals(1));
findFirst
获取第一个元素
List<Integer> list = Arrays.asList(1,2,3,4);
list.stream().findFirst().get();
list.stream().findAny().orElse(Integer.MIN_VALUE);
findAny
获取 Stream 中的某个元素,如果是串行情况下,一般都会返回第一个元素,并行情况下就不一定
List<Integer> list = Arrays.asList(1,2,3,4);
list.stream().findAny().get();
list.stream().findAny().orElse(Integer.MIN_VALUE);
reduce
它的作用是每次计算的时候都用到上一次的计算结果,比如求和操作
List<Long> list = Arrays.asList(1L,3L,3L,3L);
list.stream().map(l -> BigDecimal.valueOf(l)).reduce(BigDecimal.ZERO, BigDecimal::add);
toArray
collection是返回列表、map 等,toArray是返回数组,有两个重载,一个空参数,返回的是Object[]
List<String> list = Arrays.asList("1","3","3","3");
Object[] objectArr= list.stream().toArray();
List<User> userList = Arrays.asList(new User(18,"张三"),new User(16,"李四"),new User(20,"王五"));
Object[] userArr= list.stream().toArray(User[]::new);
collection
在进行了一系列操作之后,我们最终的结果大多数时候并不是为了获取 Stream 类型的数据,而是要把结果变为 List、Map 这样的常用数据结构
List<String> list = Arrays.asList("1","3","3","3");
list.stream().collect(Collectors.toList());
Collectors用法
1. Collectors.toList()
将stream转换为list。
List<String> list = Arrays.asList("1","3","3","3");
list.stream().collect(Collectors.toList());
2. Collectors.toSet()
toSet将Stream转换成为set
List<String> list = Arrays.asList("1","3","3","3");
Set<String> set = list.stream().collect(Collectors.toSet());
3. Collectors.toCollection()
需要自定义,则可以使用toCollection()
List<String> list = Arrays.asList("1","3","3","3");
list.stream().collect(Collectors.toCollection(LinkedList::new));
4. Collectors.toMap()
toMap接收两个参数,第一个参数是keyMapper,第二个参数是valueMapper:
List<String> list = Arrays.asList("1","3","4","5");
Map<String, Integer> mapResult = list.stream().collect(Collectors.toMap(Function.identity(),String::length));
5. Collectors.collectingAndThen()
collectingAndThen允许我们对生成的集合再做一次操作。
List<String> list = Arrays.asList("1","3","4","5");
List<String> collectAndThenResult = list.stream()
.collect(Collectors.collectingAndThen(Collectors.toList(), l -> new ArrayList<>(l)));
6. Collectors.joining()
Joining用来连接stream中的元素
List<String> list = Arrays.asList("1","3","4","5");
String str = list.stream().collect(Collectors.joining(","));
// 输出 1,3,4,5
7. Collectors.counting()
返回元素个数
List<String> list = Arrays.asList("1","3","4","5");
long str = list.stream().collect(Collectors.counting());
8. Collectors.summarizingDouble/Long/Int()
对stream中的元素做统计操作
List<String> list = Arrays.asList("1","3","4","5");
DoubleSummaryStatistics summingResult = list.stream().collect(Collectors.summarizingDouble(i->Double.valueOf(i)));
IntSummaryStatistics summingResultInt = list.stream().collect(Collectors.summarizingInt(i->Integer.valueOf(i)));
LongSummaryStatistics summingResultLong = list.stream().collect(Collectors.summarizingLong(i->Long.valueOf(i)));
//输出 DoubleSummaryStatistics{count=4, sum=13.000000, min=1.000000, average=3.250000, max=5.000000}
9. Collectors.averagingDouble/Long/Int()
对stream中的元素做平均操作
List<String> list = Arrays.asList("1","3","4","5");
Double summingResult = list.stream().collect(Collectors.averagingDouble(i->Double.valueOf(i)));
Double summingResultInt = list.stream().collect(Collectors.averagingInt(i->Integer.valueOf(i)));
Double summingResultLong = list.stream().collect(Collectors.averagingLong(i->Long.valueOf(i)));
10. Collectors.summingDouble/Long/Int()
对stream中的元素做sum操作
List<String> list = Arrays.asList("1","3","4","5");
Double summingResult = list.stream().collect(Collectors.summingDouble(i->Double.valueOf(i)));
int summingResultInt = list.stream().collect(Collectors.summingInt(i->Integer.valueOf(i)));
Long summingResultLong = list.stream().collect(Collectors.summingLong(i->Long.valueOf(i)));
11. Collectors.maxBy()/minBy()
根据提供的Comparator,返回stream中的最大或者最小值
List<String> list = Arrays.asList("1","3","4","5");
String max = list.stream().collect(Collectors.maxBy(Comparator.naturalOrder())).get();
String min = list.stream().collect(Collectors.minBy(Comparator.naturalOrder())).get();
//Comparator.naturalOrder() 自然顺序
12. Collectors.groupingBy()
根据条件分组
List<User> userList = Arrays.asList(new User(18,"张三"),new User(16,"李四"),new User(20,"王五"),
new User(20,"小李"),new User(18,"小盘"),new User(18,"小琪"));
Map<Integer, List<User>> groupByResultList = userList.stream().collect(Collectors.groupingBy(i->i.getAge(), Collectors.toList()));
Map<Integer, Set<User>> groupByResultSet = userList.stream().collect(Collectors.groupingBy(i->i.getAge(), Collectors.toSet()));
//计数
Map<Integer, Long> counting = userList.stream().collect(Collectors.groupingBy(i->i.getAge(),Collectors.counting()));
13. Collectors.partitioningBy()
特殊的groupingBy,key为Boolean
List<User> userList = Arrays.asList(new User(18,"张三"),new User(16,"李四"),new User(20,"王五"),
new User(20,"小李"),new User(18,"小盘"),new User(18,"小琪"));
Map<Boolean, List<User>> groupByResultList = userList.stream().collect(Collectors.partitioningBy(i->i.getAge()>18, Collectors.toList()));
Map<Boolean, Set<User>> groupByResultSet = userList.stream().collect(Collectors.partitioningBy(i->i.getAge()>18, Collectors.toSet()));
在map中使用stream
查找value
Map<String, String> someMap = new HashMap<>();
someMap.put("jack","20");
someMap.put("bill","35");
// 查找age=20的key
Optional<String> optionalName = someMap.entrySet().stream()
.filter(e -> "20".equals(e.getValue()))
.map(Map.Entry::getKey)
.findFirst();
查找多个值
Map<String, String> someMap = new HashMap<>();
someMap.put("jack","20");
someMap.put("bill","35");
someMap.put("alice","20");
// 多个值
List<String> listnames = someMap.entrySet().stream()
.filter(e -> e.getValue().equals("20"))
.map(Map.Entry::getKey)
.collect(Collectors.toList());
使用stream获取map的value
List<String> listAges = someMap.entrySet().stream()
.filter(e -> e.getKey().equals("alice"))
.map(Map.Entry::getValue)
.collect(Collectors.toList());
并行流
默认线程
parallelStream其实就是一个并行执行的流,它通过默认的ForkJoinPool,可能提高你的多线程任务的速度。
测试一下
@Test
void contextLoads() {
IntStream list = IntStream.range(0, 10);
Set<Thread> threadSet = new CopyOnWriteArraySet<>();
//开始并行执行
list.parallel().forEach(i -> {
Thread thread = Thread.currentThread();
System.err.println("integer:" + i + "," + "currentThread:" + thread.getName());
threadSet.add(thread);
});
System.out.println("all threads:" + threadSet.stream().map(Thread::getName).collect(Collectors.joining(":")));
}
返回值
integer:6,currentThread:main
integer:5,currentThread:main
integer:2,currentThread:ForkJoinPool.commonPool-worker-9
integer:9,currentThread:ForkJoinPool.commonPool-worker-13
integer:0,currentThread:ForkJoinPool.commonPool-worker-6
integer:7,currentThread:ForkJoinPool.commonPool-worker-4
integer:1,currentThread:ForkJoinPool.commonPool-worker-11
integer:3,currentThread:ForkJoinPool.commonPool-worker-13
integer:8,currentThread:ForkJoinPool.commonPool-worker-2
integer:4,currentThread:ForkJoinPool.commonPool-worker-9
all threads:main:ForkJoinPool.commonPool-worker-9:ForkJoinPool.commonPool-worker-13:ForkJoinPool.commonPool-worker-6:ForkJoinPool.commonPool-worker-4:ForkJoinPool.commonPool-worker-11:ForkJoinPool.commonPool-worker-2
从运行结果里面我们可以很清楚的看到parallelStream同时使用了主线程和ForkJoinPool.commonPool创建的线程。
默认的线程数量就是你的处理器数量
自定义线程
ForkJoinPool customThreadPool = new ForkJoinPool(4);
IntStream list = IntStream.range(0, 10);
Set<Thread> threadSet = new CopyOnWriteArraySet<>();
//开始并行执行
customThreadPool.submit(() -> list.parallel().forEach(i -> {
Thread thread = Thread.currentThread();
System.err.println("integer:" + i + "," + "currentThread:" + thread.getName());
threadSet.add(thread);
})
);
System.out.println("all threads:" + threadSet.stream().map(Thread::getName).collect(Collectors.joining(":")));
返回值: 可以看到这里已经使用我们定义的ForkJoinPool线程
all threads:
integer:6,currentThread:ForkJoinPool-1-worker-1
integer:5,currentThread:ForkJoinPool-1-worker-1
integer:7,currentThread:ForkJoinPool-1-worker-1
integer:8,currentThread:ForkJoinPool-1-worker-3
integer:2,currentThread:ForkJoinPool-1-worker-2
integer:9,currentThread:ForkJoinPool-1-worker-1
integer:4,currentThread:ForkJoinPool-1-worker-2
integer:1,currentThread:ForkJoinPool-1-worker-3
integer:0,currentThread:ForkJoinPool-1-worker-0
integer:3,currentThread:ForkJoinPool-1-worker-1
Stream异常处理
RuntimeException
运行时异常,可以通过编译,但是上面有一个问题,如果list中有一个0的话,就会抛出ArithmeticException。
@Test
void contextLoads() {
List<Integer> integers = Arrays.asList(1,2,0,4,5);
integers.forEach(consumerWrapperWithExceptionClass(i -> System.out.println(1 / i), ArithmeticException.class));
}
static <T, E extends Exception> Consumer<T> consumerWrapperWithExceptionClass(Consumer<T> consumer, Class<E> clazz) {
return i -> {
try {
consumer.accept(i);
} catch (Exception ex) {
try {
E exCast = clazz.cast(ex);
System.err.println("Exception occured : " + exCast.getMessage());
} catch (ClassCastException ccEx) {
throw ex;
}
}
};
}
checked Exception
checked Exception是必须要处理的异常,这个例子是编译不过去的必须要将throwIOException方法try-catch,简单但是破坏了lambda表达式的最佳实践。代码变得臃肿。
//在编译期间,我们仍然会得到同样的未处理IOException错误.
@Test
void contextLoads() {
List<Integer> integers = Arrays.asList(3, 9, 7, 0, 10, 20);
integers.forEach(i -> writeToFile(i));
}
static void writeToFile(Integer integer) throws IOException {
// logic to write to file which throws IOException
}
我们也可以封装一下异常
@FunctionalInterface
public interface ThrowingConsumer<T, E extends Exception> {
void accept(T t) throws E;
}
@Test
void contextLoads() {
List<Integer> integers = Arrays.asList(3, 9, 7, 0, 10, 20);
integers.forEach(throwingConsumerWrapper(i -> writeToFile(i)));
}
static void writeToFile(Integer integer) throws IOException {
// logic to write to file which throws IOException
}
static <T> Consumer<T> throwingConsumerWrapper(
ThrowingConsumer<T, Exception> throwingConsumer) {
return i -> {
try {
throwingConsumer.accept(i);
} catch (Exception ex) {
throw new RuntimeException(ex);
}
};
}